
한국거래소와 네이버에서 스크래핑을 하는 pykrx 라이브러리를 이용해 종목정보를 가져와보는 작업을 합니다.
상장되어있는 기업들의 정보 확인하기
일단 클래스를 하나 정의합니다. 사실 클래스로 안만들고 모듈로만 만들어도 큰 상관은 없을 것 같습니다.
korean_market_factor_data.py
import datetime
import pandas as pd
import FinanceDataReader as fdr
from pykrx import stock
class KoreanMarketFactorData:
def __init__(self):
self.stock = stock #pykrx stock library
self.fdr_data = fdr.StockListing("KRX") #FinanceDataReader library
.
.
.여기서 fdr.StockListing("KRX") 의 경우 한국거래소에 상장되어있는 종목들의 정보를 선언하는 시점에서 아래와 같은 형태로 한 번에 받아옵니다.

종목코드와 종목명 확인하기
우선은 한국거래소에 상장되어있는 기업들을 확인해야겠습니다. pykrx 라이브러리에서 제공하는 아래 2개의 메소드를 이용하면 티커와 기업명을 얻어올 수 있습니다.
- get_market_ticker_list
- get_market_ticker_name
티커로 대부분의 메소드를 사용할 수 있지만, 티커만 있으면 나중에 결과물을 볼 때 이게 무슨 기업인지 알 기 힘듭니다. 그래서 티커를 이용해서 다시 종목명을 받아오는 작업을 합니다. 위 메소드를 이용하여 데이터를 조합하면 티커와 종목명을 만들어 볼 수 있습니다.
def __get_korean_stock_ticker_and_name(self, date, market):
stock_list = pd.DataFrame({'종목코드': self.stock.get_market_ticker_list(date, market=market)})
stock_list['종목명'] = stock_list['종목코드'].map(lambda x: stock.get_market_ticker_name(x))
.
.
.date 는 조회할 날짜입니다. 넣지않으면 가장 최근의 영업일 기준으로 조회해주는 것 같습니다.
market 은 거래소의 구분입니다. pykrx 라이브러리는 아래와 같이 구분하고 있더라구요.
- KOSPI
- KOSDAQ
- KONEX
저는 여기서 코스피와 코스닥 시장만 조회해서 합칠 것이므로, 전체를 조회하지 않고 따로 조회가 가능하게끔 구분해주었습니다.
OpenDartReader나 pykrx에서 다루는 데이터포맷이 대부분 Dataframe의 형태라서, Dataframe의 객체를 생성해줍니다. 생성하면서 Key:Value 형태로 생성합니다.
이때는 stock_list 객체에 종목코드 컬럼밖에 없는 상황인데, 여기다가 종목명 컬럼도 생성해줍니다. 간단하게 변수를 선언하듯이 하면 자동으로 생성됩니다.
이후 각각의 종목코드를 map을 이용해서 하나하나 종목명을 조회해줍니다.
근데 이렇게만 하면 종목코드와 종목명 밖에 알 수가 없습니다. pykrx라이브러리는 해당 종목의 업종까지는 제공해주지 않아서, 따로 업종을 조회해야합니다.
종목의 업종 조회하기
여기서, 클래스 생성자에 FinanceDataReader의 객체를 생성해놓은 것을 사용합니다.
def __get_korean_stock_ticker_and_name(self, date, market):
stock_list = pd.DataFrame({'종목코드': self.stock.get_market_ticker_list(date, market=market)})
stock_list['종목명'] = stock_list['종목코드'].map(lambda x: stock.get_market_ticker_name(x))
stock_list['업종'] = stock_list['종목명'].map(lambda x: self.fdr_data[self.fdr_data["Name"]==x]["Sector"].iloc[0])
return stock_liststock_list 가 가지고 있는 종목명과, fdr_data 가 가지고 있는 이름이 일치하면, 그 일치하는 행의 Sector 컬럼의 값을 업종 으로 가져옵니다.
여기서 종목코드가 아닌 종목이름으로 조회한 것은, FinanceDataReader의 경우 종목코드 앞자리가 0으로 시작하는 경우에는, 0이 누락되어있었기에 종목이름으로 조회하였습니다.
사용하는 라이브러리는 다르지만, 어차피 상장된 종목을 대상으로 하는 것은 변하지 않습니다. 또한 FinanceDataReader의 경우 채권 등의 정보도 가져오지만, pykrx에서 조회한 종목명에 일치하는 종목의 업종만 추려내기 때문에 문제는 없을 것 같습니다.
이렇게 하면 벌써 종목코드, 종목명, 업종 을 얻어올 수 있게 되었습니다.
기업들의 시가총액/거래량/거래대금/상장주식수 조회하기
한 편으로, pykrx의 get_market_cap 을 이용해서 전체 종목의 조회한 시점의 시가총액,거래량,거래대금, 상장주식수을 조회해볼 수 있습니다.
def __get_fundamental_data_market_cap(self, today):
stock_list = self.stock.get_market_cap(today)
stock_list = stock_list.reset_index()
stock_list.rename(columns={'티커': '종목코드'}, inplace=True)
return stock_list
나중에 다른 데이터들과 합칠 예정이기 때문에 기존에 티커로 설정되어있는 인덱스를 리셋해주고, 티커 라고 설정되어있는 컬럼명을 종목코드 로 변경합니다.
기업들의 기본적인 펀더멘털 데이터 얻어오기
pykrx의 get_market_fundamental 을 이용해서 전체 종목의 기본적인 펀더멘털 데이터를 얻어올 수 있습니다.
제공받을 수 있는 데이터는 아래와 같습니다.
- DIV (배당률)
- DPS (주당배당금)
- BPS (주당 순자산가치)
- PER (주가수익비율)
- EPS (주당순이익)
- PBR (주가순자산 비율)
날짜를 지정하면 해당일의 종가 기준의 데이터를 얻어옵니다.
def __get_korean_stock_fundamental(self, date, market):
stock_fud = pd.DataFrame(self.stock.get_market_fundamental(date, market=market))
stock_fud = stock_fud.reset_index()
stock_fud.rename(columns={'티커': '종목코드'}, inplace=True)
return stock_fud마찬가지로 다른 데이터들과 합쳐줄 것이기 때문에 인덱스를 리셋하고 컬럼명을 변경합니다.
조회한 데이터들을 하나로 합치기
이렇게 각각 따로따로 조회한 데이터들을 하나로 합쳐야합니다.
def __get_fundamental_data(self, market):
"""
종목코드, 종목명, 업종, 시가총액, 거래량, 거래대금, BPS, PER, PBR, EPS, DIV, DPS가 담긴 데이터를 리턴.
:return: Pandas.DataFrame
"""
today = self.__get_date() ##조회할 날짜 계산
stock_list = self.__get_korean_stock_ticker_and_name(today, market)
stock_cap = self.__get_fundamental_data_market_cap(today)
stock_list = pd.merge(stock_list, stock_cap, left_on="종목코드", right_on="종목코드")
stock_fundamental = self.__get_korean_stock_fundamental(today, market)
# 종목 코드로 조인
return pd.merge(stock_list, stock_fundamental, left_on="종목코드", right_on="종목코드")일단 stock_lis 와 stock_cap 을 merge 를 이용해 하나로 합쳐줍니다. 서로 종목코드 라는 동일한 컬럼이 있으니 종목코드 컬럼을 제외한 나머지 컬럼이, stock_list 의 정보 바로 옆으로 합쳐질 것 입니다.
그 후에 다시 기업들의 재무정보들을 stock_list와 다시 merge 해주면서 메소드의 호출 장소로 리턴합니다.
날짜 계산은 아래와 같이 넣어보았습니다.
def __get_date(self):
"""
:return weekdays
:return:
"""
today = datetime.datetime.today().strftime("%Y%m%d")
year = str(datetime.datetime.today().strftime("%Y"))
month = str(datetime.datetime.today().strftime("%m"))
date = int(datetime.datetime.today().day)
date_formated = datetime.datetime.strptime(today, "%Y%m%d") # datetime format 으로 변환
if date_formated.weekday() == 5:
if month == '12':
date -= 2 # 연말의 경우 2일을 뺀다.
else:
date -= 1 # 토요일일 경우 1일을 뺀다.
elif date_formated.weekday() == 6:
if month == '12':
date -= 3 # 연말의 경우 3일을 뺀다.
else:
date -= 2 # 일요일일 경우 2일을 뺀다.
elif date_formated.weekday() == 4 and month == '12':
date -= 1 # 연말인데 금요일이면 1일을 뺀다.
# 추석에 대한 처리
if month == '09' and year == '2020':
date -= 1
elif month == '09' and year == '2023':
date -= 3
return year + month + str(date).zfill(2)zfill 을 하는 이유는, 날짜를 2자리수로 맞추어주기 위함입니다. 1자리수라면 앞에 0을 넣어 맞춥니다.
KOSPI, KOSDAQ 데이터를 각각 조회하기
def get_kospi_market_data(self):
"""
종목코드, 종목명, 업종, BPS, PER, PBR, EPS, DIV, DPS가 담긴 데이터를 리턴.
:return: Pandas.DataFrame
"""
return self.__get_fundamental_data("KOSPI")
def get_kosdaq_market_data(self):
"""
종목코드, 종목명, 업종, BPS, PER, PBR, EPS, DIV, DPS가 담긴 데이터를 리턴.
:return: Pandas.DataFrame
"""
return self.__get_fundamental_data("KOSDAQ")KOSPI, KOSDAQ을 따로따로 호출할 경우도 있을 것 같아, 각각의 패턴으로 생성했습니다.
결과물 확인하기
extract
일단 추후 작업을 위해, 데이터를 추출하고 데이터기반으로 새로운 팩터데이터를 계산하는 extract.py를 생성합니다.
from .basic_factor_data.korean_market_factor_data import KoreanMarketFactorData
class Extract:
def __init__(self):
self.factor_data = KoreanMarketFactorData()
def get_data(self):
print("Getting data from KRX")
pd.set_option('display.max_columns', None)
df_kospi = self.factor_data.get_kospi_market_data()
df_kosdaq = self.factor_data.get_kosdaq_market_data()
return pd.concat([df_kospi, df_kosdaq])로그 상에서 진행되는 진행상황을 확인하기 위한 프린트문과, 터미널에서 직접 데이터 상황을 확인할 때에 모든 컬럼이 표시될 수 있도록 set_option을 설정합니다.
이후 코스피, 코스닥 데이터를 조회해와 concat으로 하나로 합칩니다.
merge는 컬럼이 늘어나는 식으로 옆으로 붙이는 형태였다면, concat은 로우가 늘어나는 식으로 아래로 붙이는 형태입니다.
export_to_excel
한 편, 조회하고 계산된 데이터를 편하게 보기 위해서, csv나 excel로 내보낼 것 입니다.
MS Office를 이용하지 않는 분이더라도 일단 excel로 내보내기를 하신 후에 구글 스프레드시트 등에 업로드하셔서 볼 수 있습니다.
import array
import pandas as pd
class ExportToData:
def __init__(self):
self.pandas = pd
def export_to_excel(self, file_path, file):
print("Exporting result to excel file.....")
writer = self.pandas.ExcelWriter(file_path, engine='openpyxl')
file.to_excel(writer, sheet_name="test")
writer.save()지정한 경로에 엑셀파일을 생성합니다. 경로를 넣으실때 엑셀파일의 이름까지 지정해주셔야합니다.
main
여태까지 만든 결과물을 한 번 내보내기 해봅니다.
from extract_data.extract import Extract
from export_data import ExportToData
extractor = Extract()
exporter = ExportToData()
kospi_kosdaq_data = extractor.get_data()
exporter.export_to_excel("test.xlsx", kospi_kosdaq_data)이렇게 작성한 다음 파이참에서 main.py를 실행시킵니다.
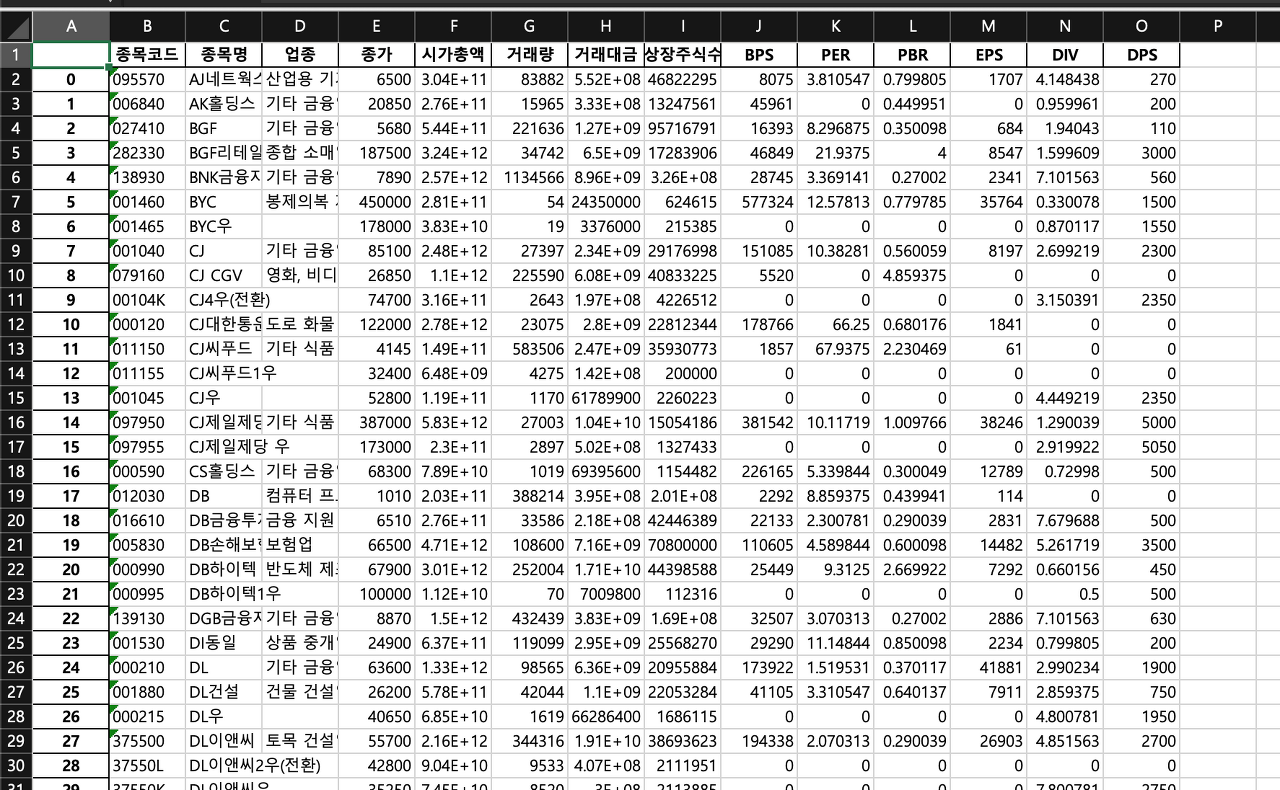
이렇게 어느정도 써먹을 수 있을 정도의 데이터가 만들어졌습니다.
다음 포스트에서는 직전 3개년의 재무정보를 읽어와 각 종목별로 넣고, 추가 데이터를 계산해보는 내용을 작성하겠습니다.
ref
'파이썬으로 종목 스크리너 만들기' 카테고리의 다른 글
| 뇌동매매 금지 - 6. 스크리닝 결과를 엑셀로 저장할 메소드 만들기 (0) | 2022.09.12 |
|---|---|
| 뇌동매매 금지 - 5. 추출하고 계산한 분기별 데이터 검증해보기 (0) | 2022.09.12 |
| 뇌동매매 금지 - 4. 팩터데이터 계산해보기, 기본 필터조건 만들어보기 (0) | 2022.09.12 |
| 뇌동매매 금지 - 3. 분기별 재무정보 조회해보기 (0) | 2022.09.12 |
| 뇌동매매 금지 - 1. 파이썬 종목 스크리닝을 위한 준비 (0) | 2022.09.12 |




댓글